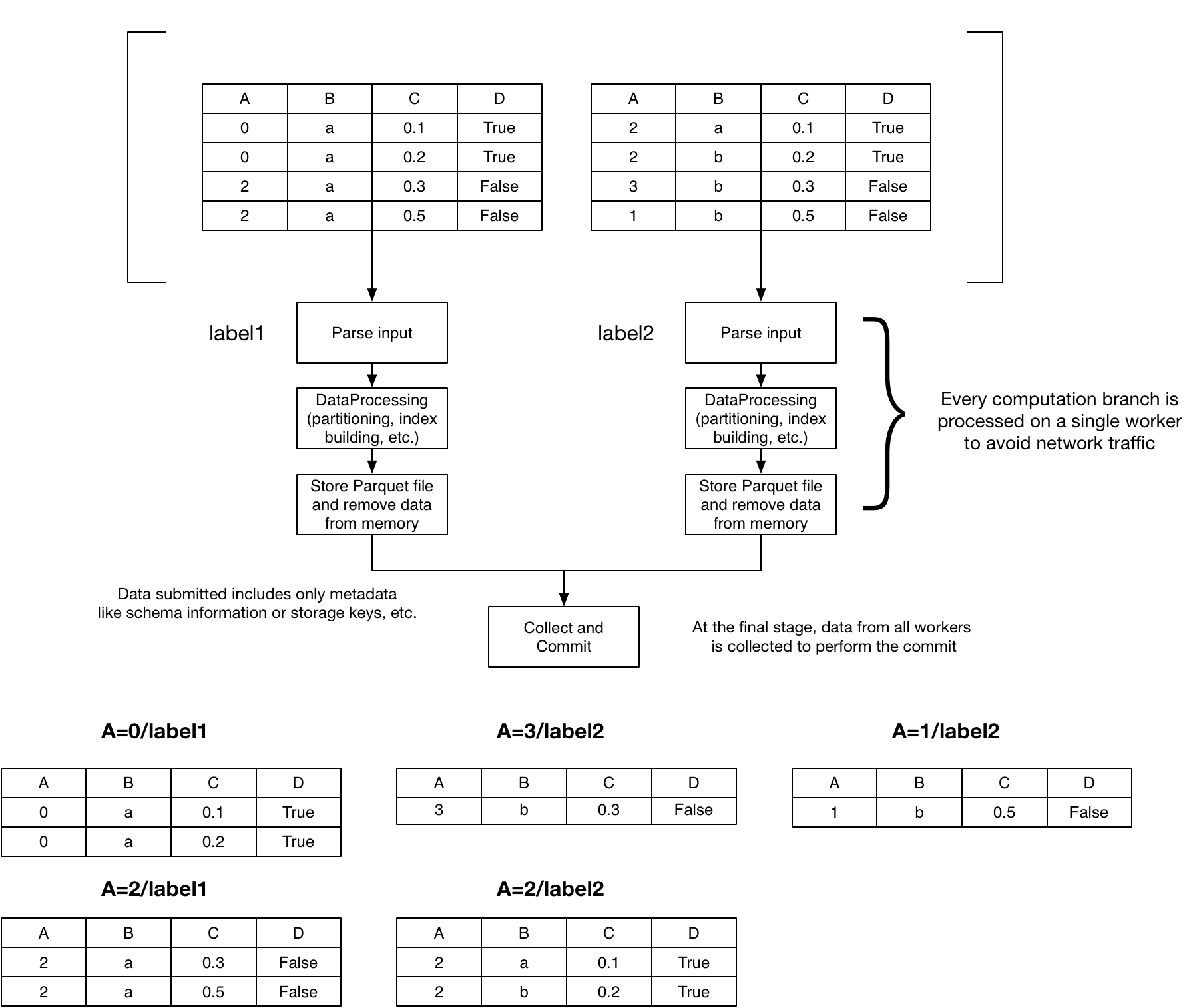
Parallel Execution with Dask
You should understand plateau’s Querying Process.
Queries
plateau executes queries with a task for every parquet file to read. But plateau doesn’t read every file. It filters them by the predicate’s restrictions on partitions and indexed columns.
The example dataset in the following pictures is partitioned on column A.
The bottom half shows the existing parquet files; the upper half shows the
querying process with the (possibly) created tasks. We filter the data for
A=2 AND B="b". plateau only processes the files A=2/label1.parquet
and A=2/label2.parquet because of the restriction on the partitioned column
A.
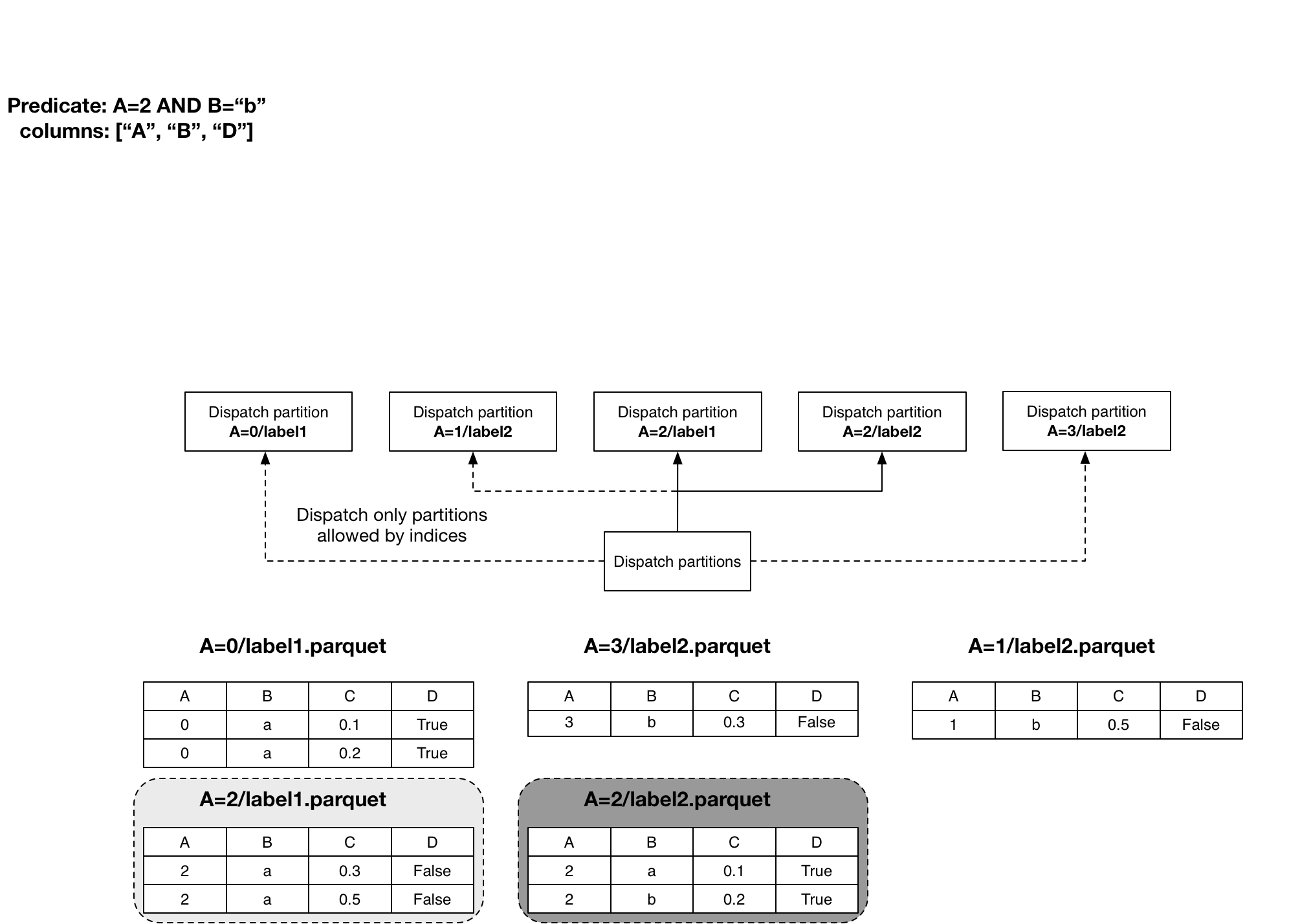
plateau matches every file’s range of values (stated in the parquet footer) against the query.
plateau rules out the existence of a row with B="b" in A=2/label1.parquet
as the Parquet statistics state both the minimum and maximum of column B to
be "a". Thus, plateau doesn’t read this file and only reads
A=2/label2.parquet.
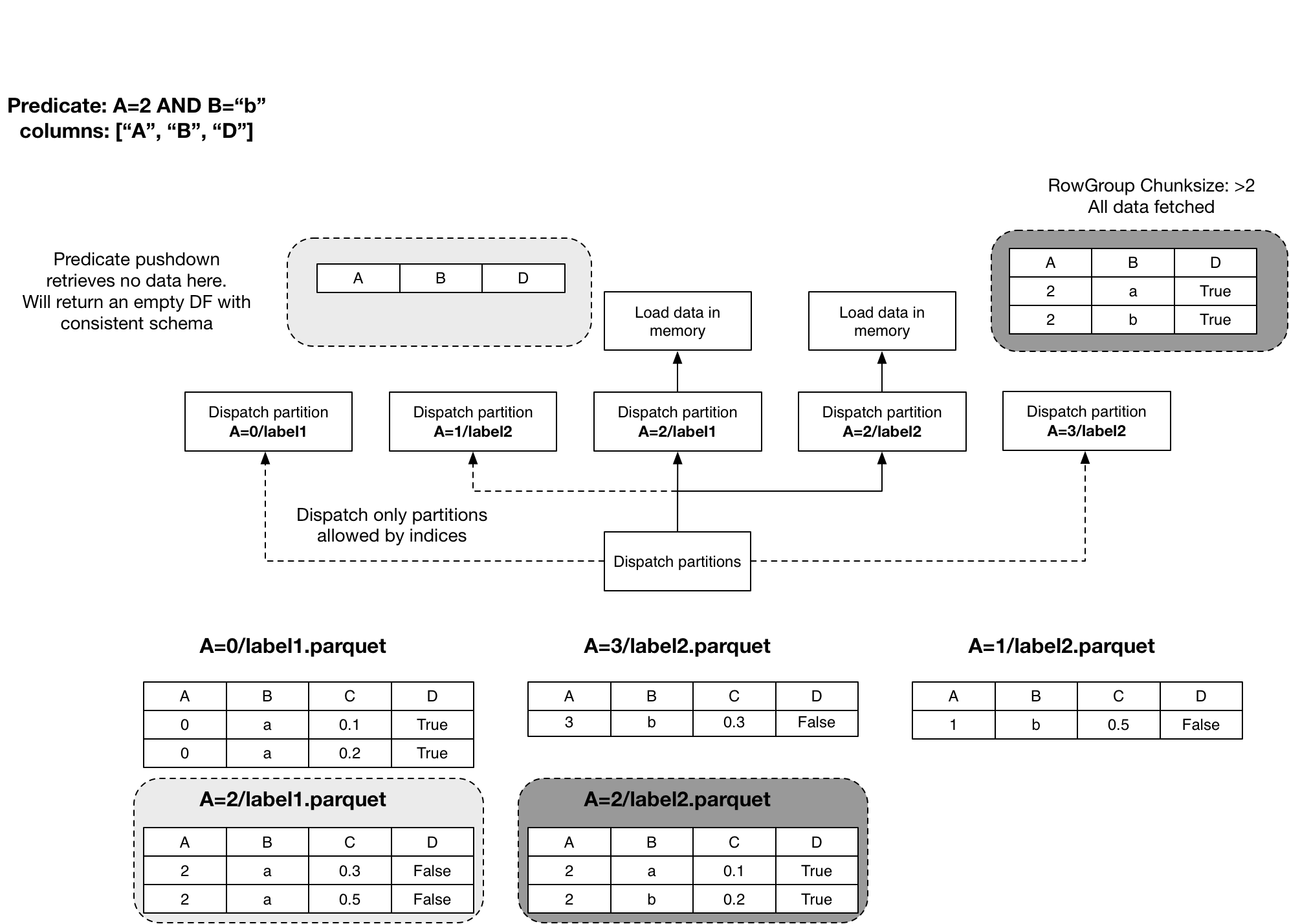
If a file’s range of values doesn’t match, the task returns an empty Dataframe. Otherwise, the task loads the file and filter its data.
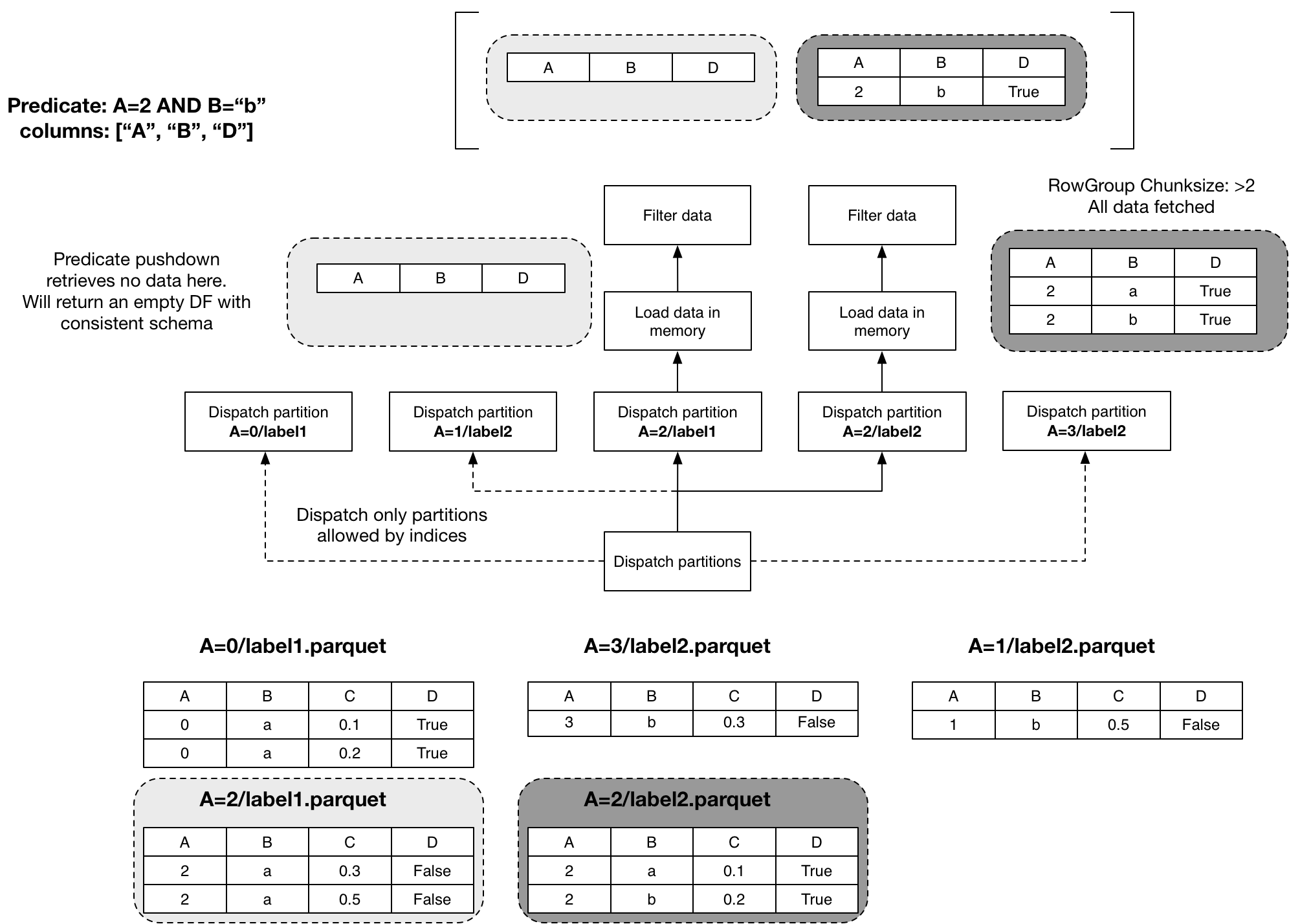
The loaded dataframes then make up the result.
Writes
If shuffle == False (default) the graph of tasks stays the same as it was
for creating the dataset that we supplied to be stored. The tasks have to split
up their chunk of data according to the partitioning scheme. So every task
writes these partitions into multiple distinct files, one into every folder for
a specific partition.
If shuffle == True, the data has to be grouped according to the
partition_on, bucket_by and num_buckets parameters. Dask handles the
distribution of data. If we’re running on a cluster, it sends the data over the
network between the workers. More information can be found in Dask’s
documentation.
At the end of either case, the results of the writes are collected and finally atomically committed to plateau’s dataset.